Versioned Merkle Tree
Ethereum manages its state via a two-layered architecture: a Merkle Patricia Trie (MPT) is built on top of a backend database (e.g, LevelDB or RocksDB).
- The MPT serves as an authenticated data structure (ADS) guaranteeing data integrity. It also provides a mechanism to verify the presence of specific data within the state. Nodes in the MPT are connected via hashes, and each node is stored in the underlying database: leaf nodes hold actual key-value pairs, while internal nodes contain metadata (e.g., hashes) about their children.
- The backend database helps persist data to disks. This backend database is often LSM-based: LevelDB or RocksDB.
A read to the state involves traversing the MPT from its root down to the target leaf node. During this traversal, the MPT must fetch the content of each node from the backend database (if not cached). Due to the LSM tree structure of the database, each query itself involves multiple disk accesses. Consequently, a single read operation often translates into many I/O operations. This amplification effect worsens as the state size increases. 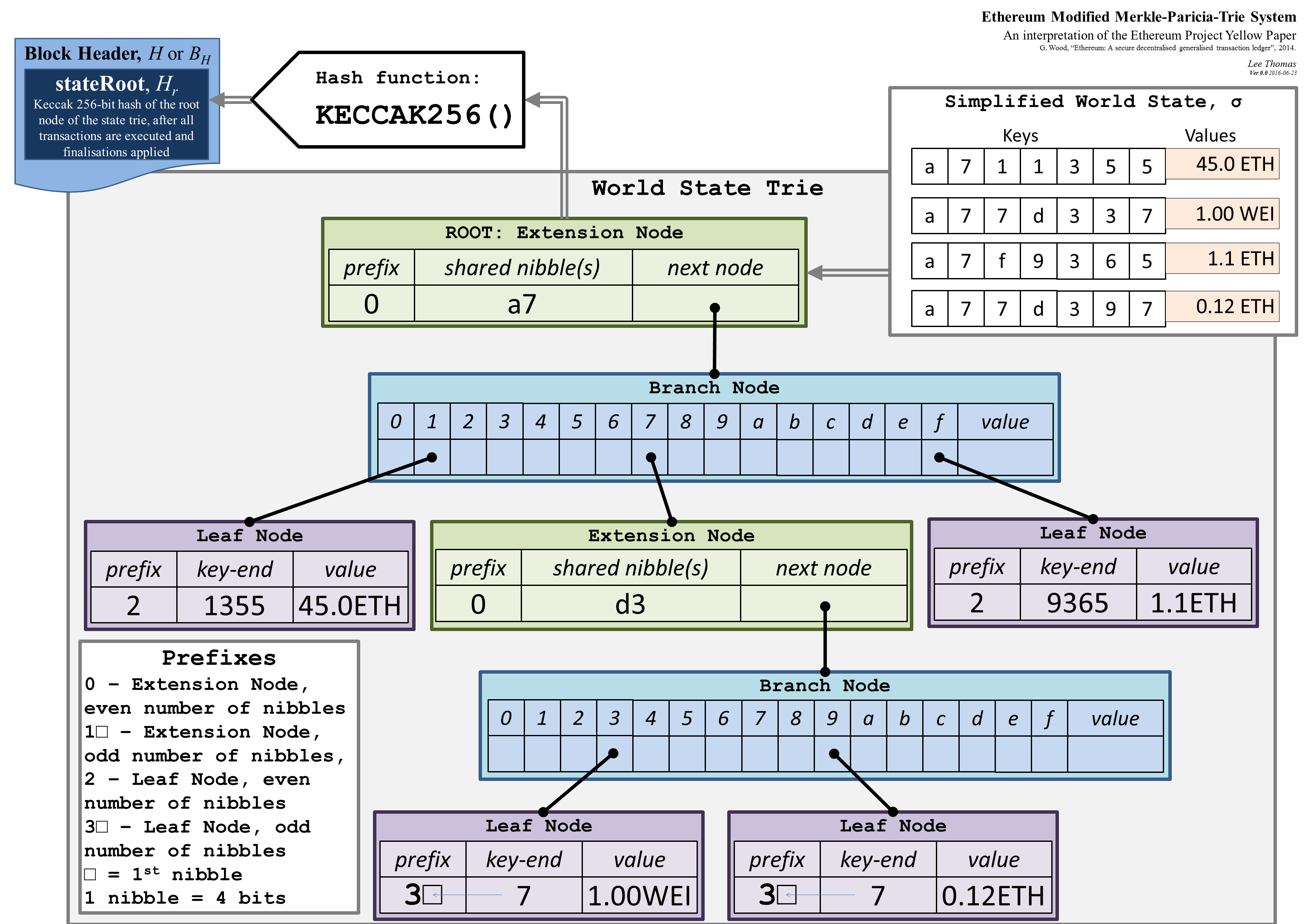 A simplified version of the Ethereum’s MPT (source: CSDN). All keys have the same
A simplified version of the Ethereum’s MPT (source: CSDN). All keys have the same a7 prefix so an extension node is created to save space and redundancy. The same goes for a77d337 and a77d397 which share the same d3 prefix.
The MPT aims to reduce redundancy and I/Os by compressing nodes with a single child to form so-called extension nodes. As reads need to query all nodes along the path from the root down to the target leaf node, extension nodes help reduce the number of queries. Extension nodes are more effective when the underlying data is sparse.
The Limitations
We summarize a few problems in designing effective state accesses in Ethereum.
- Read Amplification. Because data are stored in leaf nodes, each state access requires searching the MPT from root to leaf. Each node access in the MPT also requires multiple SSTable lookups in the backend database. As a result, queries incur log-squared amplification. On the Ethereum mainnet, this log-squared amplification is roughly 50-60.
- Write Amplification. When updating a leaf node, it is required to update all nodes along its path from the root. The larger the depth of the MPT, the more amplifications it requires. Also, when updating multiple leaf nodes, similar nodes at higher levels are most likely to get updated multiple times.
- Random Distribution of Data. Nodes in the MPT are indexed via their hashes (i.e., content-addressing). While this helps detect data tampering or malicious attacks, related nodes are randomly distributed making queries incur more searching. LSM-based KV stores often have their data sorted in predefined orders, if keys are hash-based, insertions will result in random positions given the current data spectrum. As a result, compaction will consume more time and I/O.
- No Separation of Data. Moreover, non-state data and state data in Ethereum live in the same LSM-based KV store, but they have different access patterns, leading to inefficient data access.
- Unoptimized SSD Usage. The smallest unit of SSDs is a page and SSDs can’t read or write data in units smaller than a page. A page is usually 4KB in size. Most MPT implementations dedicate one page per node which only accounts for a few hundred bytes. This incurs wasteful storage consumption as the page size is many times larger than the node size. Besides, if we can cleverly organize multiple related nodes into a page, reads would be more efficient.
- Heavy Compaction. To achieve acceptable read performance, compaction is periodically performed in the background. When the state gets larger, compaction will take more time and more I/O bandwidth.
- State Growth. MPTs use extension nodes to compress nodes sharing the same prefix effectively reducing I/O lookups. As the tree grows larger, the benefits of using extension nodes decrease significantly. The likelihood of two leaf nodes having a long shared prefix in their keys is minimal.
- CPU Under Utilization. During the waiting period for disk I/O operations to complete, resources such as CPU and memory remain underutilized and inactive throughout the transaction execution process.
Versioned Merkle Tree & RiseDB
RISE employs a much more storage-efficient Versioned Merkle Tree. Versioned Merkle Trees use a version-based node key so all keys are naturally sorted on insertion. This minimises the compaction cost of the underlying key-value storage. Versioned trees also enable robust and efficient historical queries and proofs.
A popular Versioned Merkle Tree is the Jellyfish Merkle Tree (JMT) designed for Aptos. While JMT minimizes key-value storage compaction with versioned node keys, it still uses a general-purpose RocksDB with high write amplification, and compaction is triggered during pruning.
To address this, we adopt the LETUS approach, replacing the two-layered storage architecture with a streamlined one. Tree updates are delta-encoded, and key-value pairs are stored in log-structured files (not trees) to minimize read and write amplification. 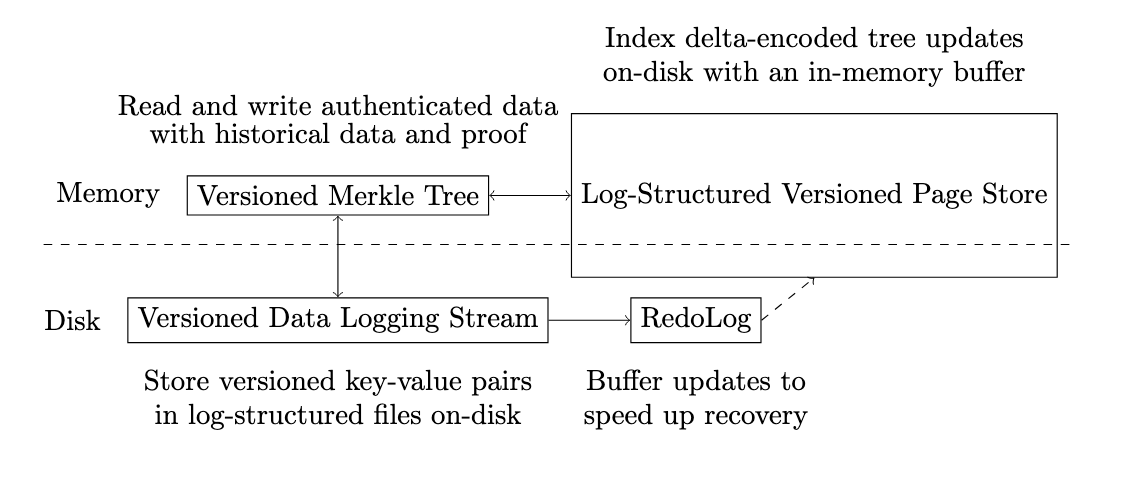
We also experiment with ideas from NOMT, lowering the radix of the Merkle tree to reduce merkelization complexity. For the increased read complexity, we use an optimal on-disk representation to parallelly fetch all subtrees for a key in one SSD round-trip. NOMT can reduce to binary as each node is only 32 bytes, but this doesn’t apply to Versioned Merkle Trees due to the extra version storage. We also store the offset and value size to index the value in the log-structured files. The final design could be an 8-ary tree to balance read and write amplification.
This structure reduces read/write amplification from high-latency disk storage and improves overall system performance. It allows RISE to process hundreds of thousands of transactions per second while managing the rapidly growing state efficiently.